コンパイルブロック
内部に含むノードのメモリアクセス抑制や並列化をさせることで主に処理の高速化に利用されるノード。

ノード概要
コンパイルブロックノード
コンパイルブロックで囲んだ内部はいくつかの挙動を制限するかわりに高速化とfor each並列処理の利用ができる。
Houdini Reference | Compiled Blocks
https://www.sidefx.com/docs/houdini/model/compile.html
高速化、並列処理
高速化はメモリの読み書きの頻度が減ることで巨大なジオメトリを扱う際に早くなる(らしい)。
また、このノードが最も恩恵が得られるのはループの並行処理でFor Eachブロックに専用の設定項目がある。
制約がある
コンパイルできるノードには以下のような制約がある。
- コンパイル可能なノードのみ対応
stamp()エクスプレッション非対応- ローカル変数とコンポーネント毎のエクスプレッション非対応
- 名前による内側ジオメトリ参照に非対応
- エクスプレッションの直接入力参照非対応
- For EachのStop Condition非対応
個別の説明は割愛するが特に「名前による内側ジオメトリ参照に非対応」「エクスプレッションの直接入力参照非対応」はコンパイルの特徴として大きい(後述)
補足:検証用のノードを作成
今回、速度周りの検証を行ったがHoudiniで実行速度を検証する際はボタンに関連ノードのクックを行うコマンドを設定しておくと楽。 記事では以下のようなノードを用意して利用している。
- 検証したいノードのEdit Parameter Interfaceを開く

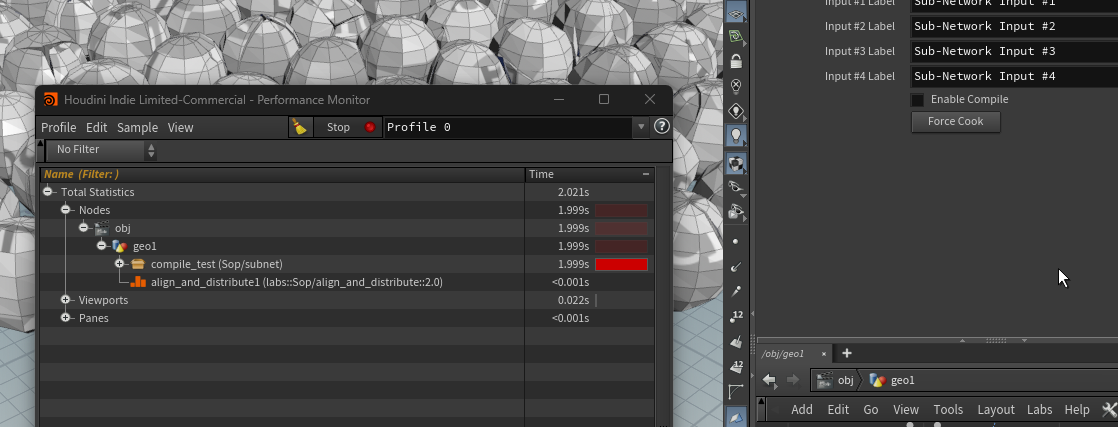
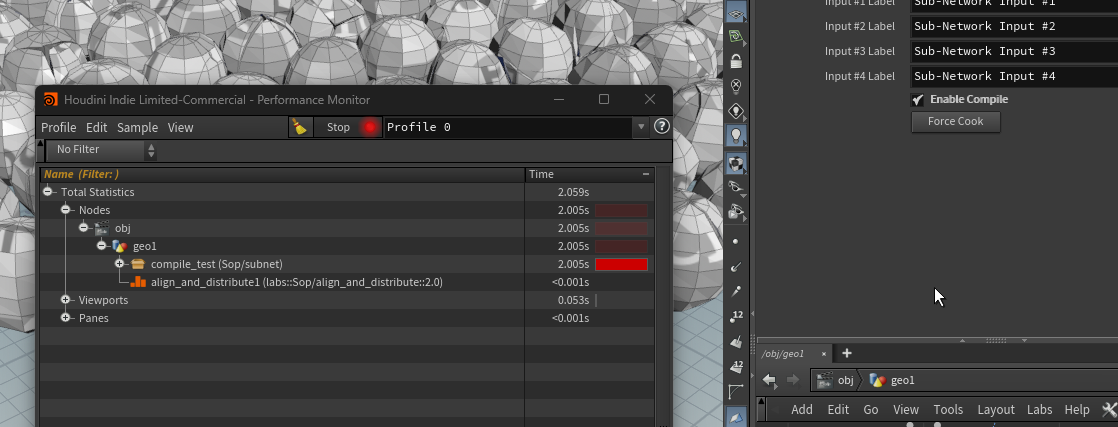
速度測定用のsubnetのParameterを設定 - Buttonを追加しCallbackScriptに一つ前のノードを強制的にクックするコマンドを設定 [画像2]
hou.pwd().input(0).cook(force=True);
CallBackスクリプトを呼び出すボタンを追加 - Window/ PerformanceMoniterからswitchでコンパイルを行う場合と行わない場合で切り替えて測定する。

コンパイルしているブロックとコンパイルしていないブロックをSwitchで切り替え 
ボタンで前のノードを強制的にcookして測定する
覚えておくべき挙動
並列処理による高速化
コンパイルブロックは処理を高速化させることに利用できるが、具体的にはfor eachのような反復処理をマルチスレッドで処理を行うことができるようになるというものである。
例えば以下のような、ただ重い処理にコンパイルブロックを設定しても速度は変わらない。
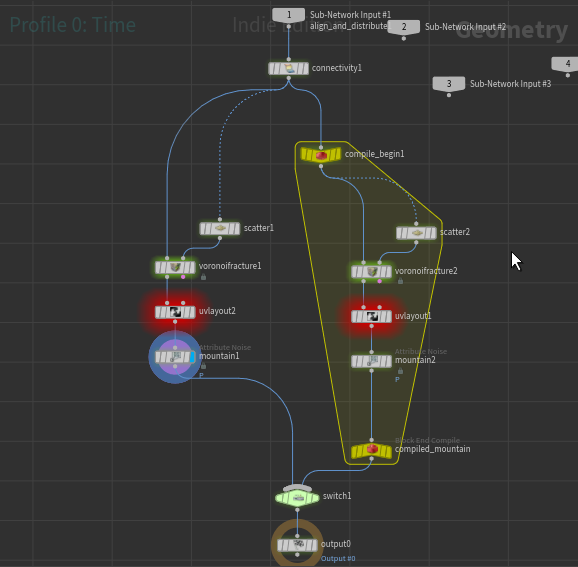
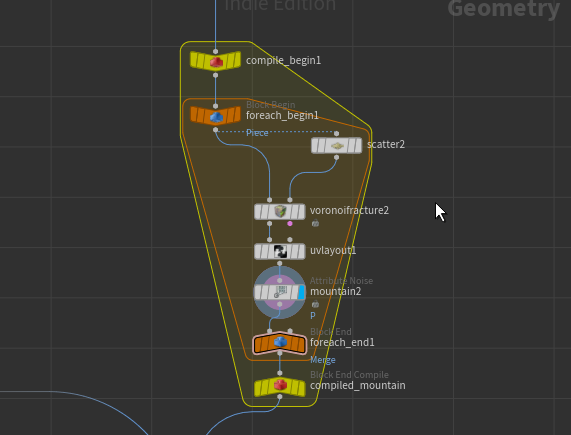
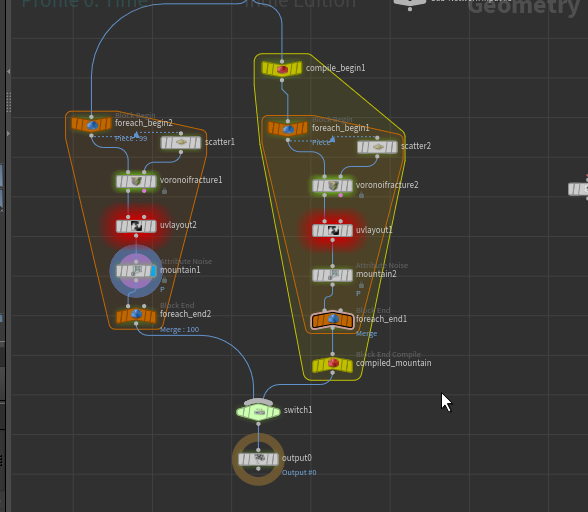
一方でSphereごとにfor eachで処理を行うノードに対しては速度の向上が見込める。
mountain、voronoi、uv layoutをまとめた処理をfor eachで回した場合、半分以下の時間で処理が完了した。
以下の例では 23.478s → 8.441sと大きく時間が減っている。何度か試したが自分の環境であれば概ね50%~40%程度減少することが確認できた。
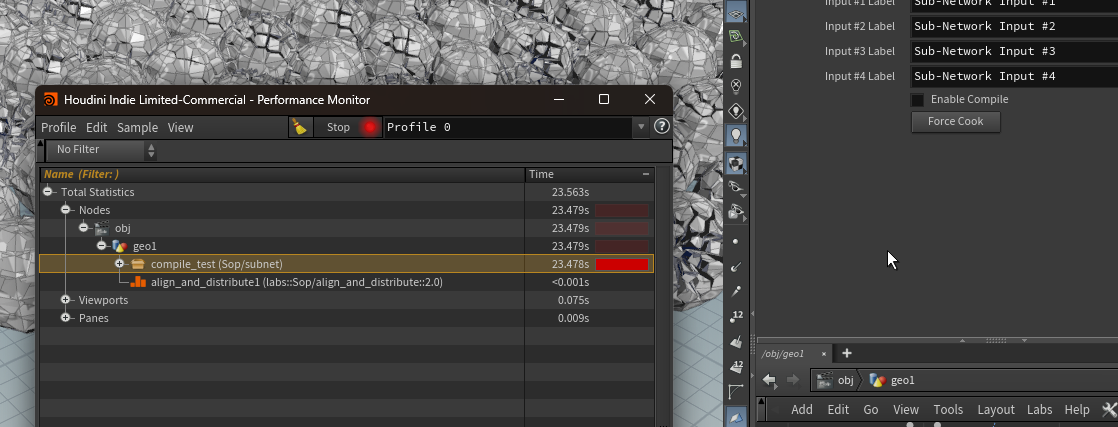
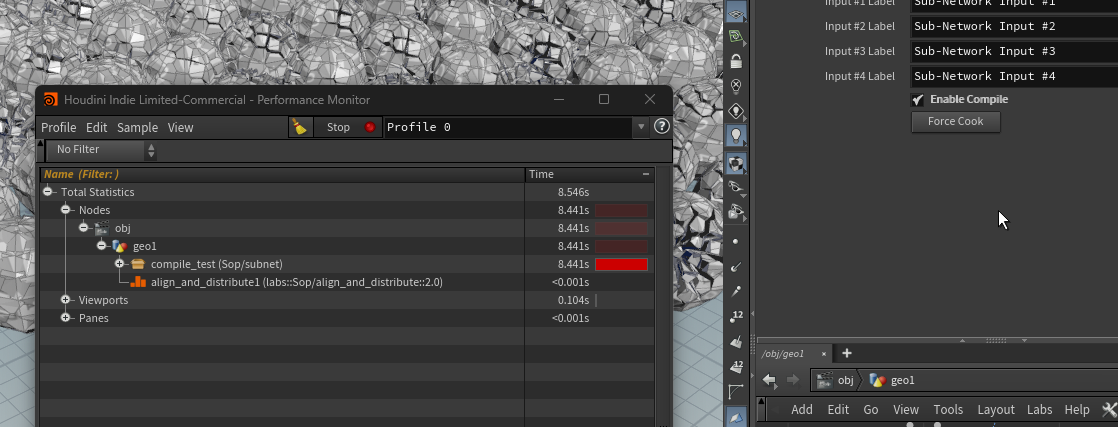
補足:個別のノードでテスト
個別で試してもForEachの並列処理はしっかり削減効果が認められた。
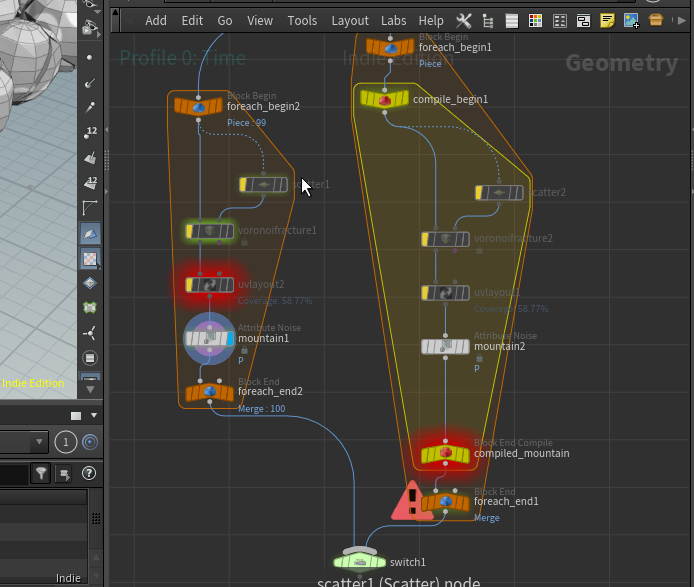
ノード | コンパイル無し | コンパイル有り |
|---|---|---|
voronoi、uv layout、 | 23.478s | 8.441s |
voronoi | 6.770s | 4.709s |
uv layout | 1.453s | 0.702s |
mountain | 0.224s | 0.069s |
コンパイル可否ノード
コンパイルはすべてのノードでできるわけではなく、可能なノードはデフォルトで表示されていないバッジで確認できる。
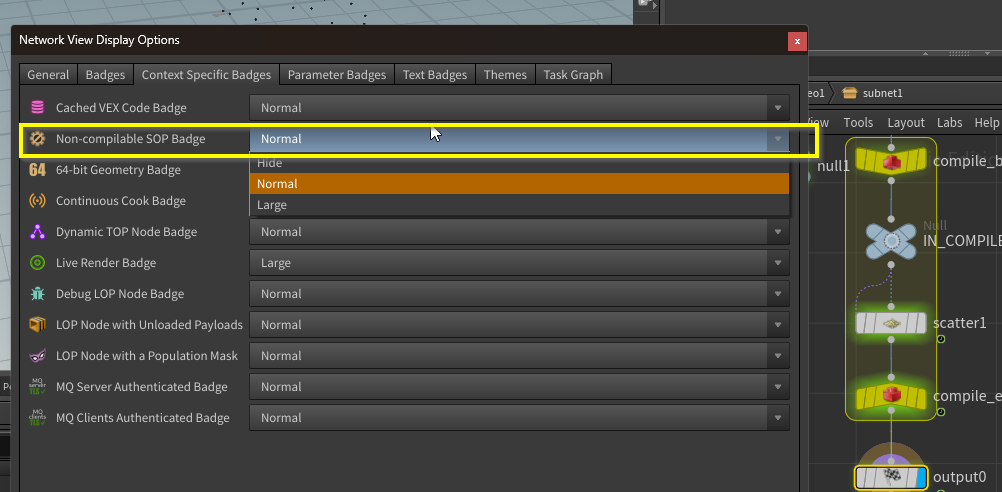
コンパイル不可なノードをコンパイルブロックに組み込むとエラーで止まる
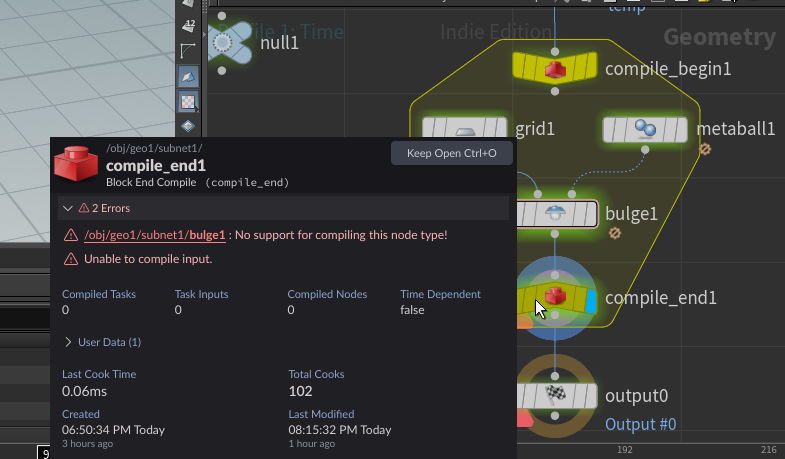
ノード参照関連の制約
前述のように参照周りで制限がいくつか存在し、特にノードを関連させる機能周りの制限が大きい。
「名前による内側ジオメトリ参照に非対応」
名前でのノード参照ができない
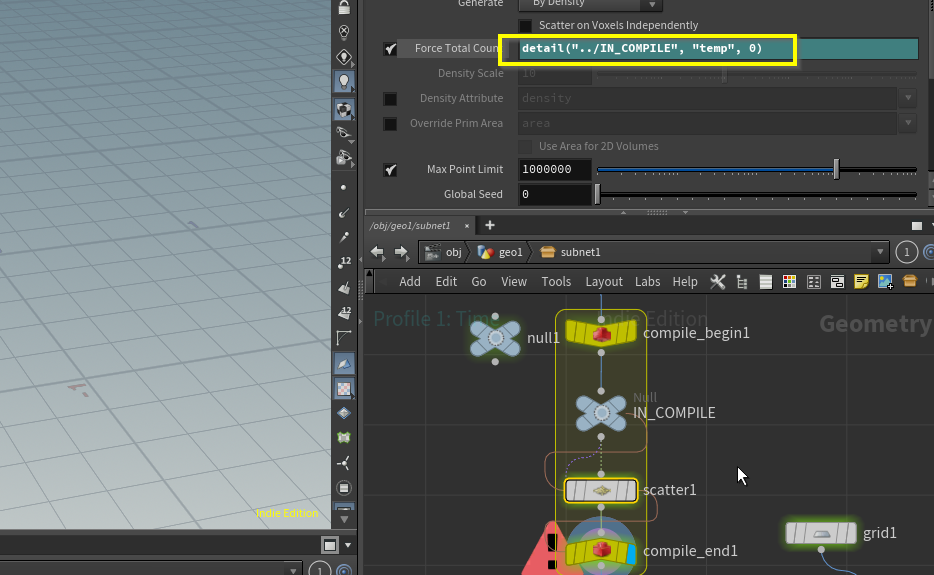
「エクスプレッションの直接入力参照非対応」
文字列だけでなく数字で行うような参照もできなくなる。
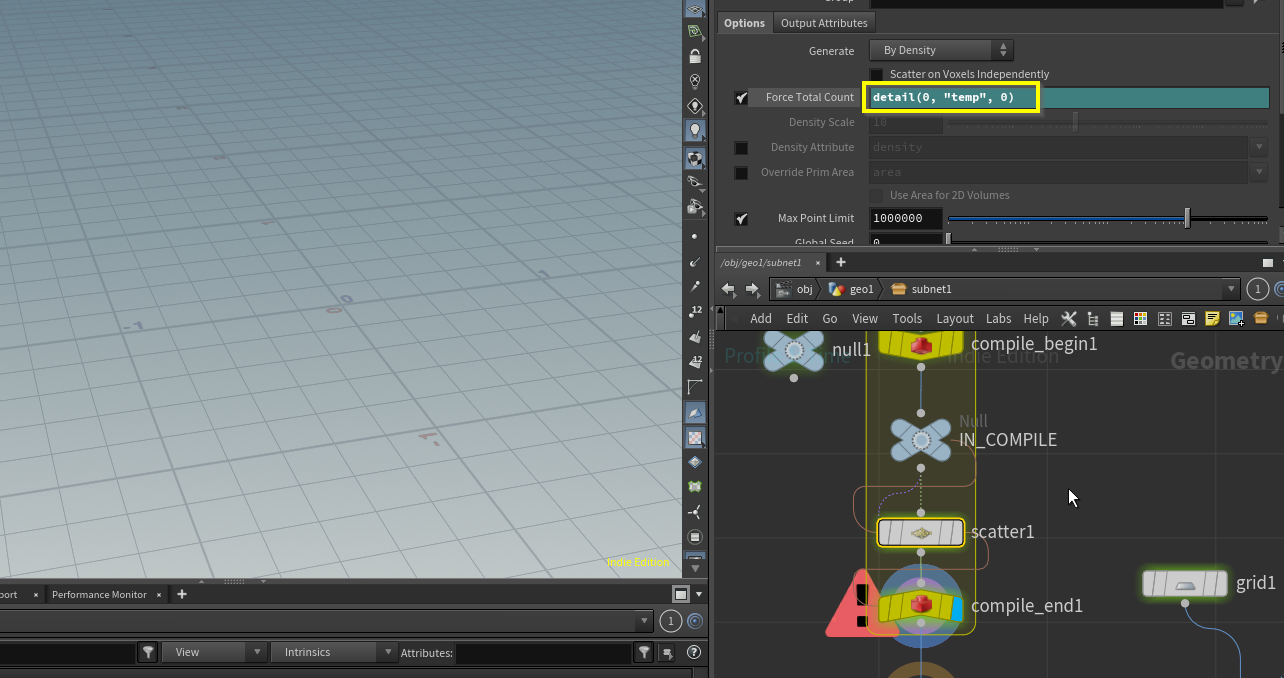
ノード参照するには
代替としてSpare Inputによる参照にするとコンパイルブロックの前に参照されると明示できるらしく、ノード参照をしたい場合はSpareInputによる参照に置き換える必要がある
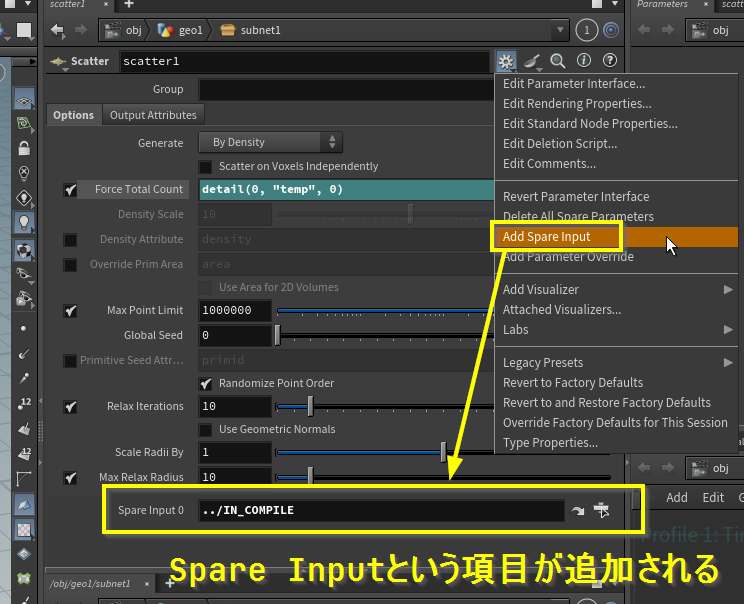
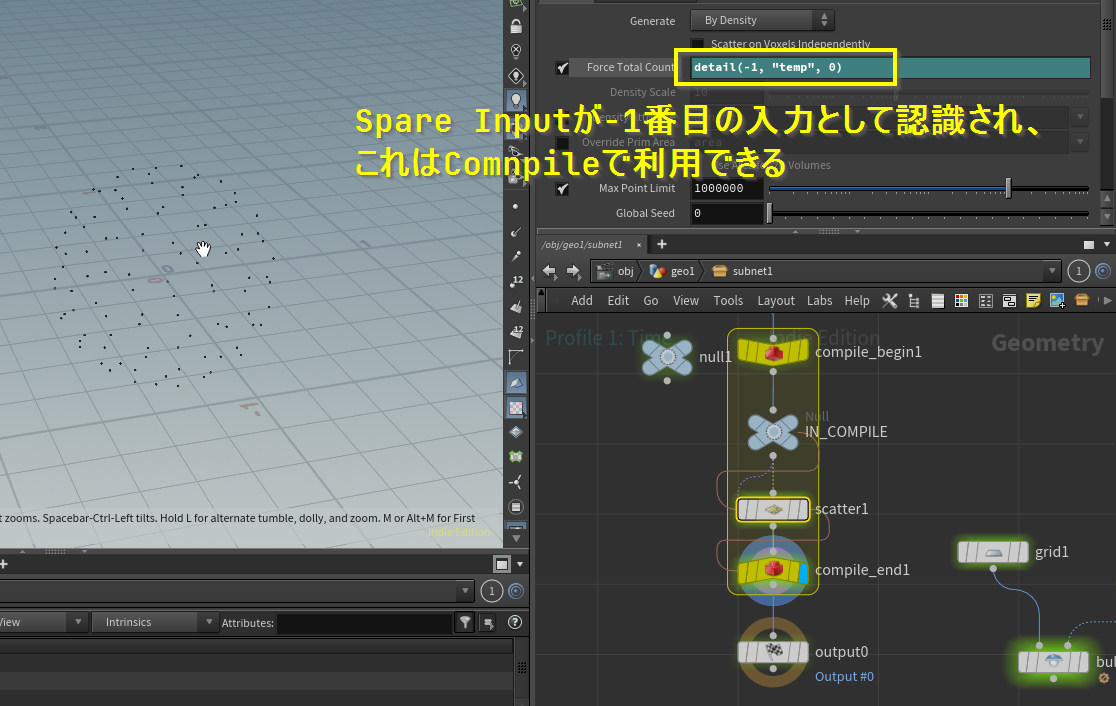
ノード参照ができない結果、それをしているHDAも利用できない
前述のように制約を内部で行っていないノードはコンパイルができない。
参照などは当然のように利用機能であるため、Labsノードなども基本的にコンパイルブロックに利用できない。
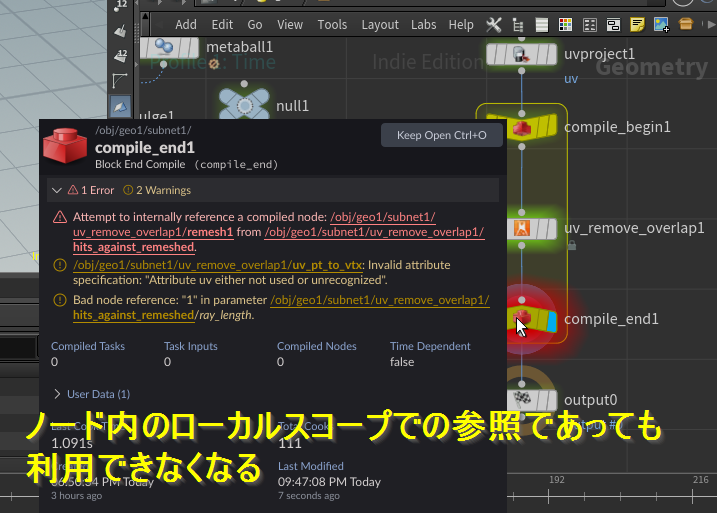
※気にしすぎない方がいい
元も子もないがリファレンスのNote項目に「コンパイルブロックをどこにでも追加しようと躍起になってしまいますが、それを我慢した方が良いでしょう。 この欠点は、その恩恵がその努力に見合わないことがよくあることです。」と記載されている。
制限項目を見てもらうとわかる通りノード参照が複雑になってしまうのでコンパイル用の構成に変更するのは労力は少なくないので基本、For Eachの重い部分だけはやっておくといい、程度の認識が良さそう。
テクニック
for each の並列化
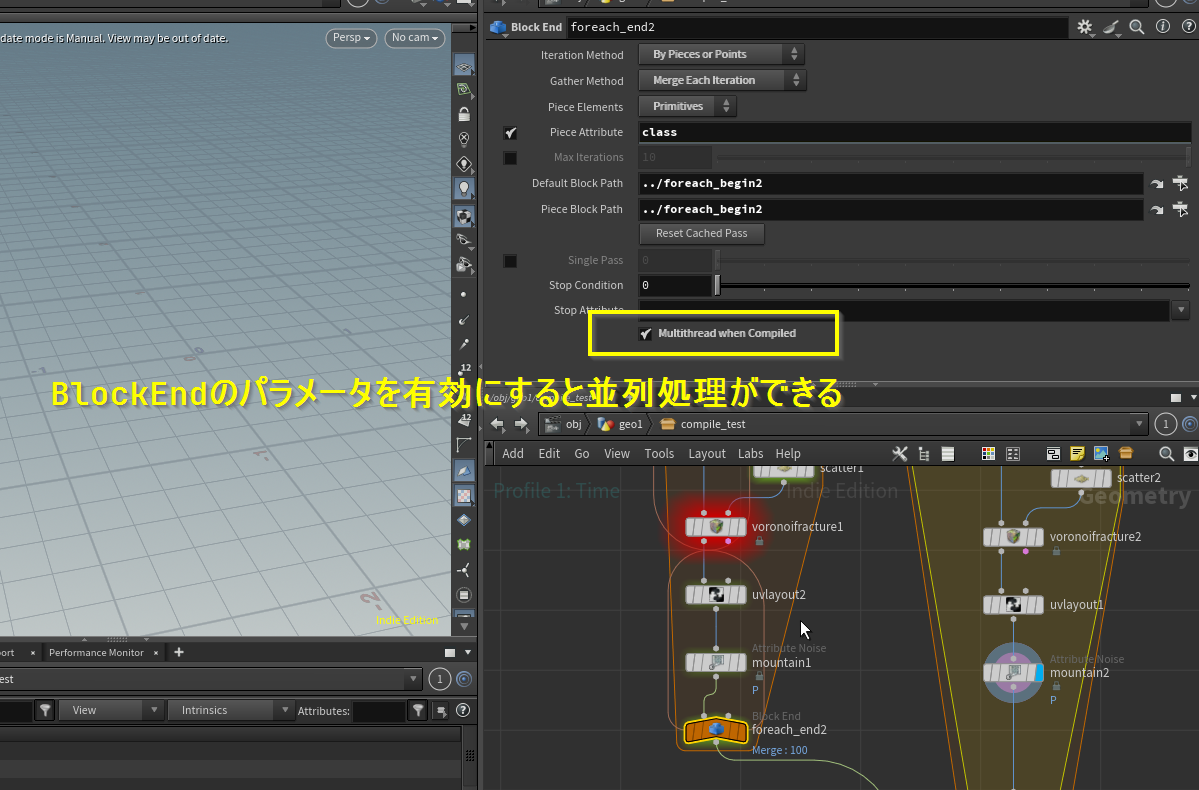
前述でも述べたがfor eachはコンパイルによる処理の並列化に対応している。 パラメータを変更しないと並列処理にしてくれないので注意(パラメータ設定しないと高速化しなかった)。
またドキュメントには複数ループがある場合は分散タスクが増えすぎないように最上位ループのみでこの設定を有効化することが推奨とされている。
ブロックの複数入力
Compileブロックに複数のノード入力をしたい場合、Compile Beginのみを追加し、2つ目のCompile BeginのBlock PathをBlock Endに指定すると一つのブロックとして認識してくれる。
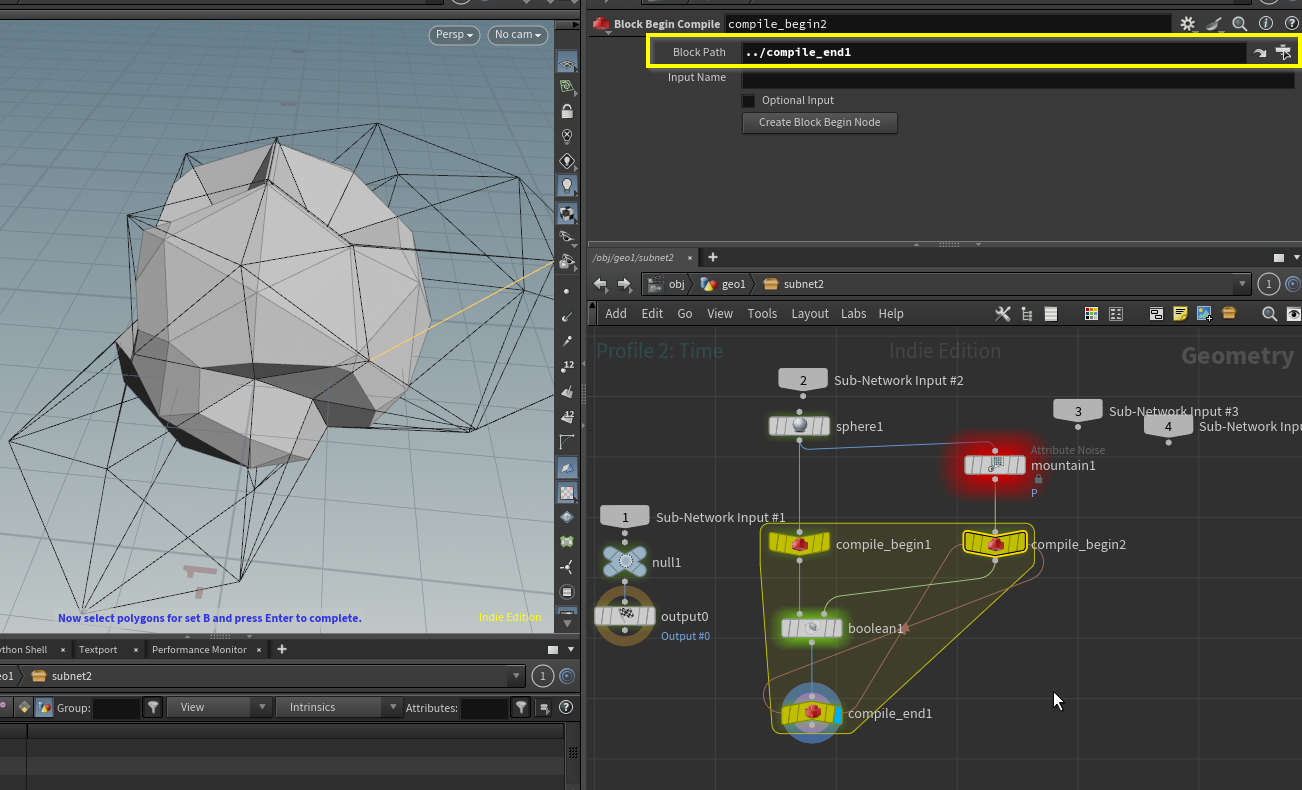
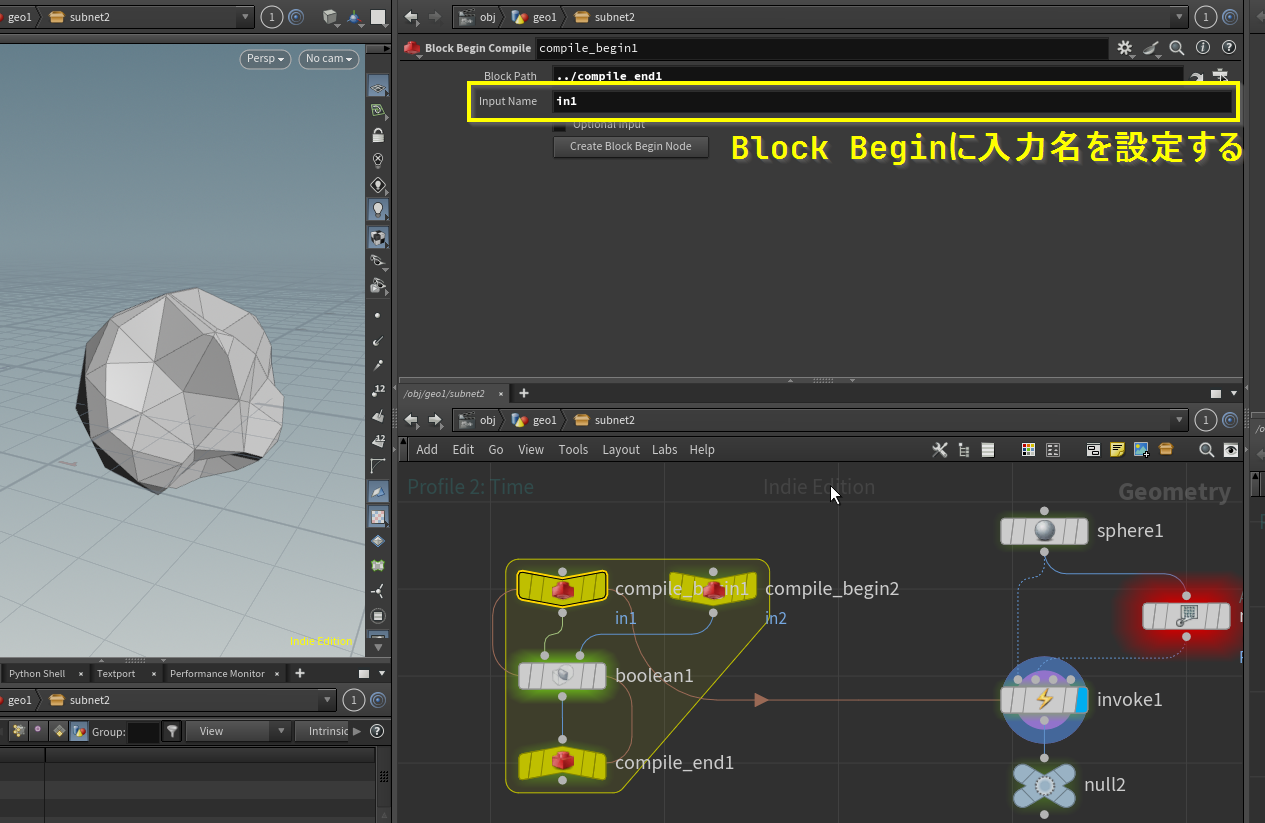
invokeを使ったコンパイルブロックの再利用
invokeノードと組み合わせればシーン内のみのローカルなHDAのように扱える。
使い回したいCompile Blockに入力名を指定する項目があるので設定し、
InvokeでCompile Block Endの指定とその入力名を設定すると同様の動作をするノードとして扱える。
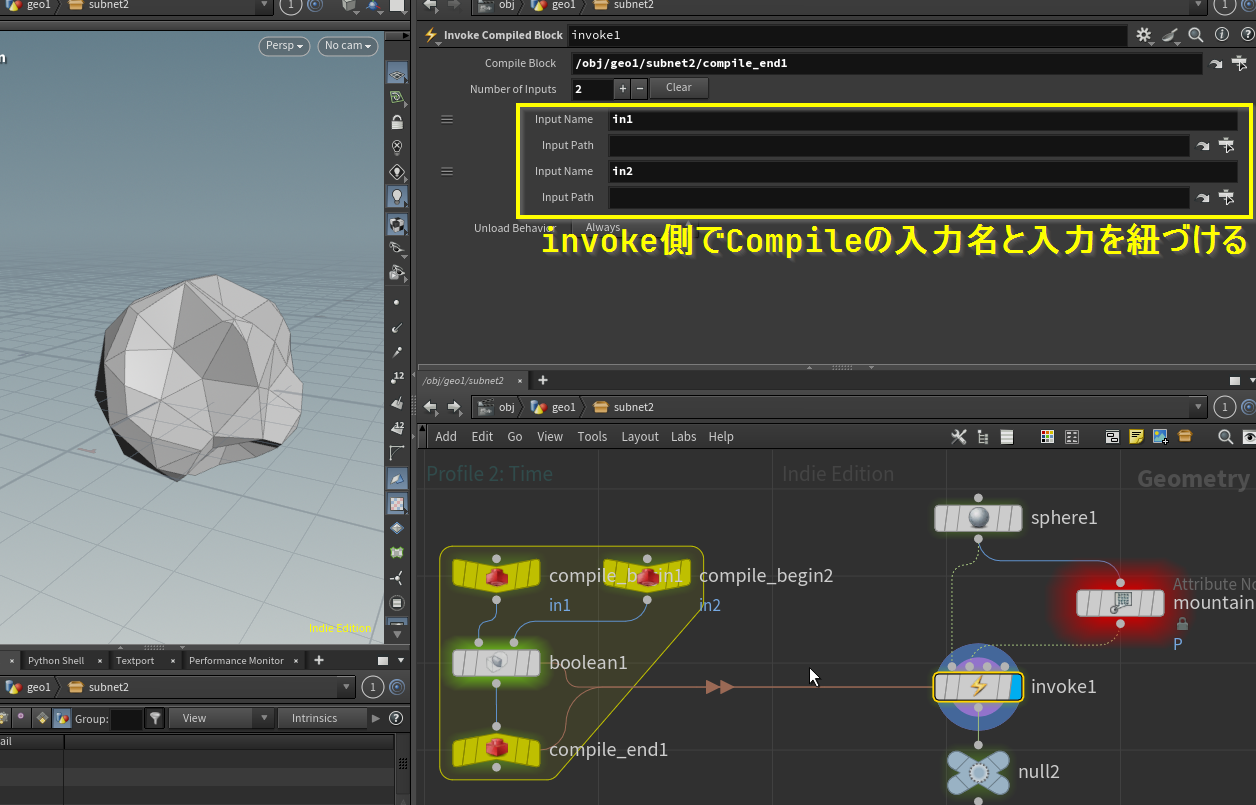
シーンだけ渡すときとかのHDA化面倒なときとかに使うといいかも。
(個人的にはコンパイルの制約管理がちょっと大変なので使い回すならHDAの方が良い気がしている)
コンパイルブロックで早くなることは聞いたことがあったのですが、どのくらいの効果があるか知らなかったのでまとめてみました。
重い処理では劇的な効果が認められそうなので仕様周りについて調べてよかったです。
AI時代が来ると大量処理の需要が今以上に増えそうですしね。

fish_ball
プロシージャル魚類